No hay muchos cursos sobre Machine Learning en Pluralsight. Buscando entre los que parecen más generales, más teóricos que prácticos, este tiene buena pinta.
Busco cursos más generalistas para ir aprendiendo los conceptos. Los más específicos, los que hablan más sobre herramientas que sobre conceptos, no me interesan todavía. Todo llegará.
Contenidos del curso How to Think About Machine Learning Algorithms de Swetha Kolalapudi:
- Course Overview
- Course Overview
- Introducing Machine Learning
- Recognizing Machine Learning Applications
- Knowing When to Use Machine Learning
- Understanding the Machine Learning Process
- Identifying the Type of a Machine Learning Problem
- Classifying Data into Predefined Categories
- Understanding the Setup of a Classification Problem
- Detecting the Gender of a User
- Classifying Text on the Basis of Sentiment
- Deciding a Trading Strategy
- Detecting Ads
- Understanding Customer Behavior
- Solving Classification Problems
- Using the Naive Bayes Algorithm for Sentiment Analysis
- Understanding When to use Naive Bayes
- Implementing Naive Bayes
- Detecting Ads Using Support Vector Machines
- Implementing Support Vector Machines
- Predicting Relationships between Variables with Regression
- Understanding the Regression Setup
- Forecasting Demand
- Predicting Stock Returns
- Detecting Facial Features
- Contrasting Classification and Regression
- Solving Regression Problems
- Introducing Linear Regression
- Applying Linear Regression to Quant Trading
- Minimizing Error Using Stochastic Gradient Descent
- Finding the Beta for Google
- Implementing Linear Regression in Python
- Recommending Relevant Products to a User
- Appreciating the Role of Recommendations
- Predicting Ratings Using Collaborative Filtering
- Finding Hidden Factors that Influence Ratings
- Understanding the Alternative Least Squares Algorithm
- Implementing ALS to Find Movie Recommendations
- Clustering Large Data Sets into Meaningful Groups
- Understanding the Clustering Setup
- Contrasting Clustering and Classification
- Document Clustering with K-Means
- Implementing K-Means Clustering
- Wrapping up and Next Steps
- Surveying Machine Learning Techniques
- Looking Ahead
Notas tomadas
Capítulo 1: Introducing Machine Learning
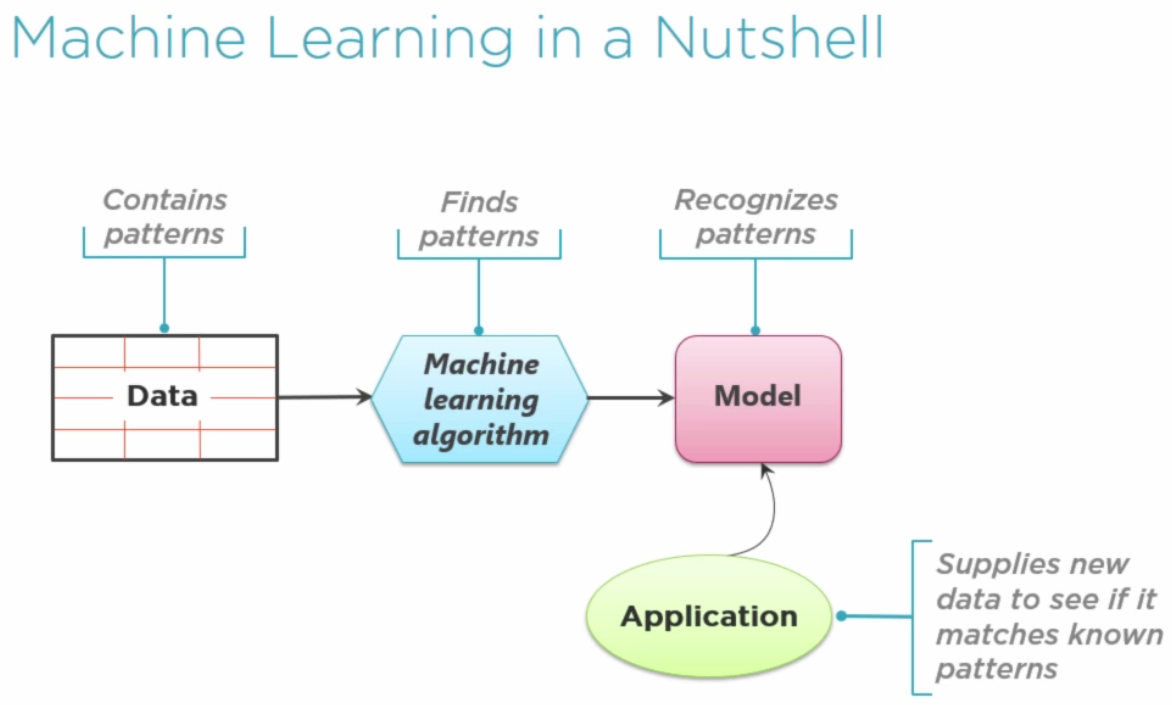
Resolver problemas con Machine Learning es como resolverlos de una manera parecida a cómo aprendemos los humanos. Los humanos aprendemos de la experiencia (exposición a un fenómeno durante un largo período de tiempo). En tecnología, esa experiencia la conocemos como datos, así, los programas aprenden de los datos como los humanos aprendemos de la experiencia.
Hay 4 grandes categorías de problemas a resolver con ML:
- Clasificación
- Regresión
- Recomendaciones
- Clustering
Los algoritmos usados en ML ya están inventados. Donde hay que emplear casi todos los esfuerzos no es en desarrollar el algoritmo, si no en ser capaz de representar los datos de forma numérica para poder aplicarlos. Lo complicado de ML no son los algoritmos, si no representar los datos de la mejor forma posible. Identificar las features correctas, cuantificarlas,…
Capítulo 2: Classifying Data into Predefined Categories
Problem instance: definición del problema que queremos resolver
Classifier: algoritmo de clasificación
Label: categoría, clasificación,… identificada
El algoritmo necesita que los datos usados en el aprendizaje estén correctamente etiquetados/clasificados.
Los patrones identificados por el algoritmo crean lo que se conoce como Modelo
Algoritmos para resolver problemas de clasificación:
- Naive Bayes
- Support vector machines
- Decision trees
- K-Nearest neighbors (K-Means?)
- Random forests
- Logistic regression
Term frequency representation: representación para cuantificar textos. Se crea una colección de todas las palabras que nos vamos a poder encontrar. Para un texto dado, anotamos las apariciones de cada una de esas palabras. Así tenemos una representación numérica del texto, con el que lo podemos comparar con otros textos.
Capítulo 3: Solving Classification Problems
Naive Bayes
Se puede utilizar para analizar textos, por ejemplo, para clasificarlos como positivos o negativos. Asumimos que los textos los tenemos cuantificados con Term freq. representation.
Para cada palabra/término tenemos que calcular la probabilidad de que aparezca
en comentarios positivos Po (la negativa sería No = 1 - Po).
(cuantas veces aparece el término en comentarios positivos)
Po = ------------------------------------------------------------
(cuantas veces aparece el término en todos los comentarios)
Para un nuevo texto dado, se multiplican los Po de cada palabra y obtenemos
el Po del comentario. Lo mismo con No.
Se llama naive porque asume que todas las palabras son independientes, cosa que sabemos que es mentira. Ciertas palabras son más probables que aparezcan junto a otras. Pero el algoritmo así es más sencillo.
Support Vector Machines
- Representa los datos como puntos en un hipercubo de
Ndimensiones (siN=3tenemos un cubo de toda la vida, un espacio tridimensional) - El algoritmo encuentra un hiperplano (en 3 dimensiones sería un plano) que divide los puntos en dos grupos. El hiperplano no es más que la línea de separación
- El hiperplano actúa como barrera, frontera entre las dos categorías
Pero… ¿cómo funciona este algoritmo? Ya tengo algo para profundizar por mi cuenta
Capítulo 4: Predicting Relationships Between Variables with Regression
En los problemas de regresión, quieres calcular, predecir algún valor contínuo. Quieres relacionar la relación que existe entre dos variables (tamaño del piso -> precio del piso).
Tipos de regresión, o algoritmos para resolver problemas de regresión:
- Lineal
- Polinomial
- No lineal
Los problemas de clasificación y los de regresión son similares en muchos aspectos. La principal diferencia es lo que obtenemos a la salida. Para la clasificación obtenemos un valor categorizado (con categorías que conocemos de antemano), mientras que para la regresión obtenemos un valor contínuo, dado unos valores de entrada (variables independientes) obtenemos un valor de salida (vble dependiente).
Capítulo 5: Solving Regression Problems
Supongamos que tenemos las variables independientes X0, X1,… La
vble dependiente será Y. Podemos calcular:
Y = b0 + b1·X1 + b2·X2 + ...
Donde b0,… son constantes. Son los valores que debe encontrar el algoritmo
de ML. Estas constantes se llaman co-eficientes.
Para unos valores encontrados de los coeficientes se calcula un error (distancia de la línea calculada hasta los puntos reales). El objetivo es minimizar este error. Una de las técnicas disponibles es Stochastic Gradient Descent.
Capítulo 6: Recommending Relevant Products to a User
Collaborative filtering algorithms: predicen valoraciones de productos de los usuarios basándose en el comportamiento pasado del usuario
Latent factor analysis: es un subconjunto de Collaborative filtering. Identifica factores ocultos que influyen en el comportamiento del usuario. Ocultos es la clave. Factores ocultos pueden ser: género, popularidad del reparto en una película, cercanía a la salida del producto al mercado,…
Partimos de una matriz donde las columnas son productos y las filas los usuarios. Cada celda es la valoración del usuario. Pero hay huecos. Tenemos que adivinar los valores para esos huecos.
| Prod 1 | Prod 2 | Prod 3 | ... | Prod n |
+--------+--------+--------+-----+--------+
Usr 1 | 5 ¿?
+--------+--------+--------+-----+--------+
Usr 2 | 6 ¿?
+--------+--------+--------+-----+--------+
Usr 3 | 10
+--------+--------+--------+-----+--------+
Usr m | ¿?
Nos inventamos dos matrices: matriz User-Factor y matriz Product-Factor, de forma que multiplicando las dos, obtendremos la matriz Product-User. Al no conocer todos los valores de Product-User, tenemos que iterar para calcular los valores de las dos matrices inventadas, que son justo las que contienen información sobre los factores ocultos.

Donde r43 es la valoración del usuario 4 para el producto 3.
Por lo cual, tenemos que resolver Rui = Pu · Qi. Al no conocer todos los valores de
Rui cometeremos errores. Hay que conseguir que esos errores sean el mínimo. Tenemos
que minimizar el error SUM(Rui - Pu·Qi)^2
Para ello se puede utilizar la técnica Alternating Least Squares
Algoritmos para resolver problemas de recomendaciones:
- Collaborative filtering: alternating least squares, nearest neighbor model
- Association rules
- Content based filtering
Capítulo 7: Clustering Large Data Sets into Meaningful Groups
Clustering es una forma de agrupar elementos basándose en alguna medida de similaridad.
El objetivo es maximizar el parecido dentro de los grupos (intracluster) y al mismo tiempo minimizar el parecido entre distintos grupos (intercluster).
Por ejemplo, se pueden representar a los usuarios mediante atributos numéricos, y dichos
puntos se pueden mostrar en un espacio de N dimensiones.
Algoritmos de clustering:
- K-Means
- Hierarchical
- Density based
- Distribution based
Los problemas de clasificación y de clustering parecen lo mismo, pero no lo son. En clasificación conocemos de antemano las categorías. En clustering no, si no que descubrimos las categorías.
En ocasiones ambos problemas van de la mano. Se usa clustering para detectar categorías. Se usan esas categorías para categorizar después nuevos datos.
Inverse document frequency: usado en conjunto con Term Frequency Representation, se
usa para minimizar el impacto de palabras muy, muy usadas en documentos (artículos la y
lo, conjunciones y y o,…). Cada frecuencia de un término se multiplica por un
factor (o weight) calculado como la inversa de los documentos en los que el término
aparece. La historia está en que palabras más usadas, tendrán menos peso en la representación
numérica.
Para hace clustering de documentos, tenemos representado cada documento por un conjunto
de N números (term frequency) ponderados (inverse document frequency). Vamos, un documento
es un punto en un espacio de N dimensiones. Si no lo has pillado a estas alturas, ya no
sé qué hacer contigo.
Algoritmo K-Means
En ese espacio de N dimensiones, se inicializan una serie de puntos como K medias. Estos
puntos son considerados centroides de los clusters que queremos identificar.
Cada punto de nuestros datos se asigna a la media más cercana. Formando así unos clusters iniciales.
Con los clusters ya montados, se calculan unos nuevos centroides o K-medias.
Repetir el proceso hasta que los centroides no se mueven (o no se mueven mucho).
Capítulo 8: Wrapping up and Next Steps
La mayoría de los datos requieren un gran preprocesado.
Representación de los datos:
- Data munging
- Feature extraction: natural language processing, image and video processing
- Dimensionality reduction
- Feature engineering: construir las features más relevantes de un conjunto en crudo de datos o features. Por ahora, este es un campo informal, considerado un black art
Selección del modelo:
- Hyper parameter tuning
- Cross validation
- Ensembling
Conclusión
Ha habido momentos durante el curso que pensé que era flojillo, pero al poco tiempo me di cuenta de que es un curso bastante bueno. Expone distintos problemas para ser resueltos mediante Machine Learning.
No todos los problemas se pueden resolver de la misma manera y Swetha explica distintos tipos de problemas y sus distintas formas de resolverlos.
Totalmente recomendado para saber por dónde van los tiros a la hora de enfrentarse a problemas. Abre muchos caminos por los que seguir aprendiendo. Y esa era mi idea, así que estoy bastante contento con el curso.
Y después… ¿qué? ¿con qué sigo?
- ¿Cómo funciona el algoritmo Support Vector Machines?
- Sería interesante saber en profundidad cómo funciona Stochastic Gradient Descent
- Sería interesante saber en profundidad cómo funciona Alternating Least Squares, otro método para minimizar errores
Referencias
- How to Think About Machine Learning Algorithms
- La autora del curso: Swetha Kolalapudi