En este asalto aprenderemos qué son los Supervisores OTP y cómo se puede crear una estructura jerárquica de ellos de forma que monitoricen nuestros procesos y sean capaz de arrancar nuevos procesos en caso de que alguno de ellos falle. También veremos cómo unos procesos sirven de ayuda para guardar el estado de aquellos procesos que necesitan ser tolerantes a fallos.
Todo esto, siguiendo el método de aprendizaje con el que comenzé la serie:
- Aprender lo suficiente para comenzar
- Experimentar, jugar, buscar puntos desconocidos, hacerse preguntas
- Aprender lo suficiente para hacer algo de utilidad
- Enseñar lo aprendido

Aprender lo suficiente para comenzar
Supervisores OTP
La forma de hacer las cosas en Elixir es no preocuparse mucho por el código que falla, si no asegurarse de que la aplicación en general sigue corriendo. Suena contradictorio, pero no lo es. En Elixir los procesos son muy pequeñitos, por lo que si uno de ellos falla, casi todo el sistema sigue funcionando. Al contrario que en otros lenguajes, donde el lanzamiento de una excepción puede hacer que todo el servidor sufra. En el mundo OTP, los supervisores son quienes monitorizan y recuperan esos procesos fallidos.
Un supervisor en Elixir tiene un único propósito: manejar uno o más workers
(otro tipo de procesos). La forma de funcionar es darle una lista de procesos e
indicarle qué hacer con cada uno de ellos en caso de que falle. La forma más
fácil de crear un supervisor es crear un nuevo proyecto con mix y usar el
flag --sup.
defmodule Sequence do
use Application
def start(_type, _args) do
import Supervisor.Spec, warn: false
children = [
worker(Sequence.Worker, [arg1, arg2, arg3])
]
opts = [strategy: :one_for_one, name: Sequence.Supervisor]
# create the supervisor with a list of workers and some options
Supervisor.start_link(children, opts)
end
end
Gestionando el estado del servidor entre reinicios
Como se puede comprobar al jugar con el supervisor y el servidor creados en el [Ejercio 01], el servidor es reiniciado, pero no mantiene el estado anterior al fallo, si no que siempre se reinicia con el estado inicial, indicado a la hora de crear el supervisor. Esto se puede mejorar.
La forma de mantener el estado es almacenándolo fuera del proceso servidor. Esto se hace mediante un nuevo worker, un nuevo servidor, al que se le llama stash. Nuestro servidor almacenará su estado actual en ese stash worker. El stash worker debe ser monitorizado por un supervisor diferente, por lo que tenemos que crear un arbol de supervisores. En este árbol, nuestro worker principal debe conocer el PID del stash, con lo que la forma de crear el árbol cambia ligeramente de la forma que hemos visto anteriormente.
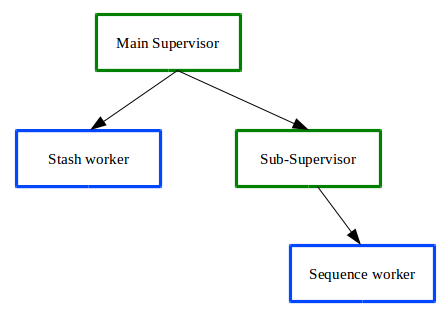
La aplicación funcionaría de la siguiente forma:
- Primero, arrancamos el supervisor raíz del árbol, pasándole el valor inicial que será el estado inicial del sistema
- Este supervisor arranca el stash worker, pasando el valor inicial (porque este worker almacenará el estado del sistema) y arranca un sub-supervisor, pasándole el PID del stash
- El sub-supervisor arranca el worker principal, el que contiene la lógica, quien incrementa el valor inicial con el que arrancamos el sistema
- El worker principal, nada más arrancar, consulta al stash worker el estado actual, y es con ese estado con el que va a trabajar
- Si el worker principal falla por cualquier causa, debe enviar su estado al stash worker, para que lo almacene
- El sub-supervisor detectará que el proceso a muerto y reiniciará de nuevo el worker principal, que leerá el estado del worker que murió del stash worker
Aprender lo suficiente para hacer algo de utilidad
-
una pila de enteros
Resultado
Increíble, increíble que sea tan fácil. Lo primero, el supervisor arranca él
solito y levanta el servidor él solito también. Super cómodo. Luego, captura
los errores y levanta de nuevo el servidor sin que nosotros tengamos que hacer
nada más. Para hacer fallar a la pila, se podía hacer con un
Stack.Server.push -1. El supervisor captura el fallo, y rearranca el
servidor.
-
creando un árbol de supervisores, y un stash worker, de forma que cuando el worker principal falle, el estado sea guardado. Comprueba que el sistema mantiene el estado cuando el worker principal falla
Enseñar lo aprendido, y repetir desde el paso 7
Aquí está, este post, mis notas, mis pensamientos, mis dudas y mi código. Hasta el siguiente asalto.